AidLite SDK for C++
简介
背景知识
深度学习中最重要的两个基础概念就是模型的 训练 与 推理。
深度学习的“训练”,我们可以把它类比成在学校中学习。你现在想要训练一个能区分苹果还是橘子的模型,你需要搜索一些苹果和橘子的图片,这些图片放在一起称为训练数据集,训练数据集是有标签的,苹果图片的标签就是苹果,橘子亦然。初始的神经网络通过不断的优化自身参数,来让自己变得准确,可能开始 10 张苹果的照片,只有 5 张被神经网络认为是苹果,另外 5 张识别错误,通过优化参数,让另外 5 张错的也变成对的,这个过程就称为训练。
完成训练之后,可以得到实现相关功能的深度学习模型,使用这个模型文件可以实现深度学习的“推理”,即可以基于其训练成果对其所获得的「新数据」进行推导。前述训练好的模型在训练数据集中表现良好,但是我们的期望是它可以对之前没看过的图片进行识别,比如我们重新拍一张包含苹果的图片扔进这个模型,也依然能够正确识别才行。
SDK简介
对于前述的训练和推理两个阶段而言,训练模型需要开发者提前完成,得到可用的算法模型,然后就可以利用这个模型来使用Aidlite-SDK完成推理过程。
Aidlite-SDK 是跨平台统一 AI 推理中间件,针对不同AI框架和不同 AI 芯片的调用进行了抽象,形成统一的 API 接口,可实现模型推理实现的解耦合。
- 兼容主流开源AI框架(TFLITE 等)。
- 兼容主流AI芯片厂商专属框架(SNPE、RKNN 等),支持厂商专属硬件(NPU)调用。
Aidlite-SDK 针对不同 AI 芯片平台的异构计算资源进行了抽象,实现了不同 AI 芯片厂商异构计算单元调用差异性的无感知化。
- CPU-通用,性能差。
- GPU-差异较少,性能较高。
- NPU-厂商专属,最高性能。
模块化底层封装实现,可快速对新AI框架和新AI芯片进行适配支持,并通过OTA方式获得更新。
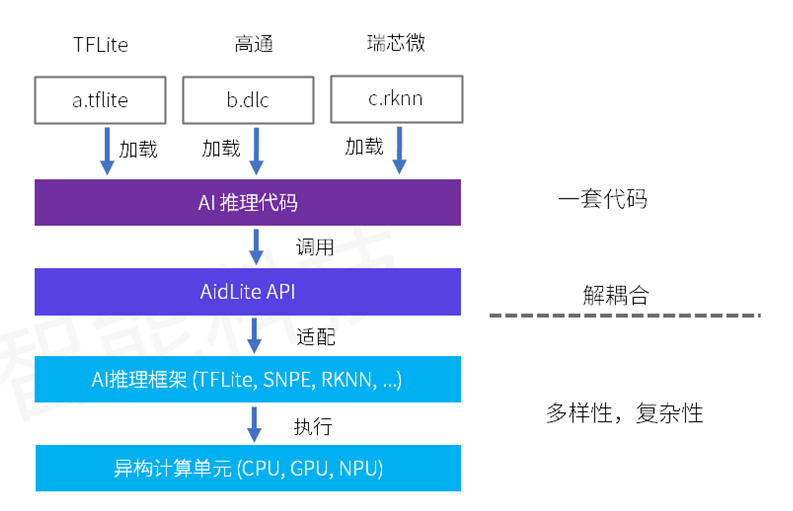
Aidlite-SDK 高度统一的 API 抽象,兼容了不同框架模型及 AI 芯片的调用,让开发人员只需进行一次开发,即可任意更换不同格式的模型或在不同厂商 AI 芯片实现迁移。大大减少了开发者的学习成本,平台迁移难度和成本。摆脱了对特定 AI 框架或者 AI 芯片的绑定,技术选型更灵活,产品落地更快速。
开发流程
Aidlite-SDK 在底层整合了多种深度学习的推理框架,所以不管具体使用的是哪个深度学习框架的模型,其推理所需流程、所需 API 都是高度统一的。
前置准备
Aidlite-SDK 是用来完成深度学习推理过程的组件,需要用到已经完成训练的深度学习算法模型,所以在使用此 SDK 之前,需要有某个深度学习框架(如 SNPE、TFLite 等)的训练好的模型文件。
一般流程
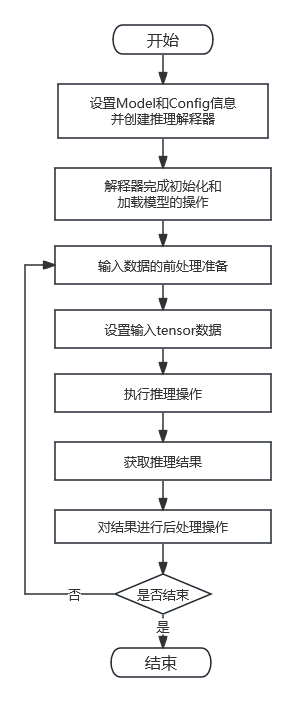
对于完整的推理流程,一般需要经过如下所示的几个步骤:
- 设置模型相关的参数,告知推理组件这个模型的详细信息,在推理过程中会使用到这些参数以更好地完成推理工作。
- 参数配置完成之后,使用这些参数生成推理解释器,并完成解释器的初始化。
- 完成模型的加载过程(加载过程的耗时长短不定)。
- 对输入数据做一些前处理操作(比如求均值、转为 float 数据类型等),得到模型推理所需的数据。
- 推理解释器设置输入数据。
- 使用推理解释器完成推理过程。
- 取出推理完成后的结果数据。
- 对于结果数据,做一些相关的后处理操作(比如找出置信度最高的分类等),得出结果。
通常来说,推理的实现过程是为模型提供不同的输入数据,然后在推理之后得到不同的输出数据,并解析输出数据看结果是否正常。所以对于相同的模型,上述第 4、5、6、7、8 步骤是持续循环执行的过程,而在此之前的步骤仅需执行一次。
差异操作
当然,在上述的统一流程中,针对不同框架的不同模型文件,也会有些具体的差异:
- 前述第 1 步骤,对于不同模型,需要不同的 Model 对象和 Config 对象的配置(如模型类型、模型输入输出数据类型等),用以告知 Aidlite-SDK 该模型相关的详细信息。
- 前述第 4 步骤,对于不同模型,需要不同的输入数据,也就有不同的前处理操作。
- 前述第 8 步骤,对于不同模型,会有不同的结果数据,也就有不同的后处理操作。
开发流程图
核心使用流程如下图所示。
快速上手
使用 Aidlite-SDK C++ 开发需要了解如下事项:
- 编译时需要包含头文件,存放路径 /usr/local/include/aidlux/aidlite/aidlite.hpp
- 链接时需要指定库文件,存放路径 /usr/local/lib/libaidlite.so
完整示例
我们先来看一个使用 Aidlite-SDK C++ 进行开发的代码示例,如下所示。
需要注意的是,下述代码仅用于展示主要开发流程,更多的接口和配置信息请详细阅读后面的 API 章节。
// 获取SDK版本信息,设置日志相关事项
printf("Aidlite library version : %s\n", Aidlux::Aidlite::get_library_version().c_str());
// Aidlux::Aidlite::set_log_level(Aidlux::Aidlite::LogLevel::INFO);
// Aidlux::Aidlite::log_to_stderr();
// Aidlux::Aidlite::log_to_file("./fast_snpe_inceptionv3_");
// 创建Model实例对象,并设置模型相关参数
Model* model = Model::create_instance("./inceptionv3_float32.dlc");
if(model == nullptr){
printf("Create model failed !\n");
return EXIT_FAILURE;
}
std::vector<std::vector<uint32_t>> input_shapes = {{1,299,299,3}};
std::vector<std::vector<uint32_t>> output_shapes = {{1,1001}};
model->set_model_properties(input_shapes, DataType::TYPE_FLOAT32,
output_shapes, DataType::TYPE_FLOAT32);
// 创建Config实例对象,并设置配置信息
Config* config = Config::create_instance();
if(config == nullptr){
printf("Create config failed !\n");
return EXIT_FAILURE;
}
config->framework_type = FrameworkType::TYPE_SNPE;
config->accelerate_type = AccelerateType::TYPE_CPU;
// config->is_quantify_model = 0;
config->snpe_out_names.push_back("InceptionV3/Predictions/Softmax");
// 创建推理解释器对象
std::unique_ptr<Interpreter>&& fast_interpreter =
InterpreterBuilder::build_interpretper_from_model_and_config(model, config);
if(fast_interpreter == nullptr){
printf("build_interpretper_from_model_and_config failed !\n");
return EXIT_FAILURE;
}
// 完成解释器初始化
int result = fast_interpreter->init();
if(result != EXIT_SUCCESS){
printf("sample : interpreter->init() failed !\n");
return EXIT_FAILURE;
}
// 加载模型
fast_interpreter->load_model();
if(result != EXIT_SUCCESS){
printf("sample : interpreter->load_model() failed !\n");
return EXIT_FAILURE;
}
//完整的推理代码示例:一般包括三部分:前处理 + 推理 + 后处理
{
// 对于不同的模型,对应不同的前处理操作
void* input_tensor_data = preprocess();
// 设置推理所需的输入数据
result = fast_interpreter->set_input_tensor(0,input_tensor_data);
if(result != EXIT_SUCCESS){
printf("sample : interpreter->set_input_tensor() failed !\n");
return EXIT_FAILURE;
}
// 完成推理操作
result = fast_interpreter->invoke();
if(result != EXIT_SUCCESS){
printf("sample : interpreter->invoke() failed !\n");
return EXIT_FAILURE;
}
// 获取模型此次推理的结果数据
float* out_data = nullptr;
uint32_t output_tensor_length = 0;
result = fast_interpreter->get_output_tensor(0, (void**)&out_data, &output_tensor_length);
if(result != EXIT_SUCCESS){
printf("sample : interpreter->get_output_tensor() failed !\n");
return EXIT_FAILURE;
}
// 对于不同的模型,对应不同的后处理操作
int32_t result = postprocess(out_data);
}
// 完成解释器资源释放操作
result = fast_interpreter->destory();
if(result != EXIT_SUCCESS){
printf("interpreter->destory() failed !\n");
return EXIT_FAILURE;
}
示例详解
下面针对刚才的示例,按照开发顺序依次进行详细讲解。
首先,为了方便调试,我们有时候会需要获取到 AidliteSDK 库的版本信息,同时也需要设置 AidliteSDK 运行时的日志记录情况。
// 获取SDK版本信息,设置日志相关事项
printf("Aidlite library version : %s\n", Aidlux::Aidlite::get_library_version().c_str());
// Aidlux::Aidlite::set_log_level(Aidlux::Aidlite::LogLevel::INFO);
// Aidlux::Aidlite::log_to_stderr();
// Aidlux::Aidlite::log_to_file("./fast_snpe_inceptionv3_");
然后,我们需要为模型文件创建对应的 Model 对象,并设置模型相关的更多信息,如模型输入输出的 shape 信息、输入输出的数据类型等等。
// 创建Model实例对象,并设置模型相关参数
Model* model = Model::create_instance("./inceptionv3_float32.dlc");
if(model == nullptr){
printf("Create model failed !\n");
return EXIT_FAILURE;
}
std::vector<std::vector<uint32_t>> input_shapes = {{1,299,299,3}};
std::vector<std::vector<uint32_t>> output_shapes = {{1,1001}};
model->set_model_properties(input_shapes, DataType::TYPE_FLOAT32,
output_shapes, DataType::TYPE_FLOAT32);
接下来,我们需要创建 Config 类型的对象,此对象用于记录模型推理相关的配置信息,推理框架运行过程中会使用到这些配置信息。需要说明的是,此处仅列出部分使用到的配置项,更多的配置项请查询 API 相关章节。同时这些配置项可能存在的默认值,以及每个配置项具体都有哪些可选值,这些都需要详细阅读 API 相关章节。
// 创建Config实例对象,并设置配置信息
Config* config = Config::create_instance();
if(config == nullptr){
printf("Create config failed !\n");
return EXIT_FAILURE;
}
config->framework_type = FrameworkType::TYPE_SNPE;
config->accelerate_type = AccelerateType::TYPE_CPU;
// config->is_quantify_model = 0;
config->snpe_out_names.push_back("InceptionV3/Predictions/Softmax");
……
创建 Model 对象和 Config 对象没有异常的情况下,配置完成之后,就可以用这个 Model 对象和 Config 对象来创建最重要的推理解释器 Interpreter 对象。并且执行初始化操作和加载模型的操作,前面的配置项很多都会在这个过程中使用到,这个过程的耗时可能会相对长一些。
// 创建推理解释器对象
std::unique_ptr<Interpreter>&& fast_interpreter =
InterpreterBuilder::build_interpretper_from_model_and_config(model, config);
if(fast_interpreter == nullptr){
printf("build_interpretper_from_model_and_config failed !\n");
return EXIT_FAILURE;
}
// 完成解释器初始化
int result = fast_interpreter->init();
if(result != EXIT_SUCCESS){
printf("sample : interpreter->init() failed !\n");
return EXIT_FAILURE;
}
// 加载模型
fast_interpreter->load_model();
if(result != EXIT_SUCCESS){
printf("sample : interpreter->load_model() failed !\n");
return EXIT_FAILURE;
}
完成前述的这些配置和创建等事项后,调用者需要完成输入数据的前处理操作。这个前处理究竟需要做些什么事情,根据调用者自己的模型不同而各异,所以此处使用伪代码带过。
// 对于不同的模型,对应不同的前处理操作
void* input_tensor_data = preprocess();
准备好输入数据之后,需要将输入数据传递给推理对象,就可以做推理操作,推理成功完成后就可以得到针对当次输入数据的推理结果。
// 设置推理所需的输入数据
result = fast_interpreter->set_input_tensor(0,input_tensor_data);
if(result != EXIT_SUCCESS){
printf("sample : interpreter->set_input_tensor() failed !\n");
return EXIT_FAILURE;
}
// 完成推理操作
result = fast_interpreter->invoke();
if(result != EXIT_SUCCESS){
printf("sample : interpreter->invoke() failed !\n");
return EXIT_FAILURE;
}
// 获取模型此次推理的结果数据
float* out_data = nullptr;
uint32_t output_tensor_length = 0;
result = fast_interpreter->get_output_tensor(0, (void**)&out_data, &output_tensor_length);
if(result != EXIT_SUCCESS){
printf("sample : interpreter->get_output_tensor() failed !\n");
return EXIT_FAILURE;
}
调用者需要对得到的输出结果数据后处理操作。这个后处理究竟需要做些什么事情,同样也是根据调用者自己的模型不同而各异,所以此处也是使用名称带过。
// 对于不同的模型,对应不同的后处理操作
int32_t result = postprocess(out_data);
最后,完成必要的资源释放工作。
// 完成解释器资源释放操作
result = fast_interpreter->destory();
if(result != EXIT_SUCCESS){
printf("sample : interpreter-> destory() failed !\n");
return EXIT_FAILURE;
}
API详细说明
使用 Aidlite-SDK C++ 开发需要了解如下事项:
- 编译时需要包含头文件,存放路径 /usr/local/include/aidlux/aidlite/aidlite.hpp
- 链接时需要指定库文件,存放路径 /usr/local/lib/libaidlite.so
模型数据类型.enum DataType
对于 AidliteSDK 而言,会处理不同框架的不同模型,每个模型自己也有不同的输入数据类型和不同的输出数据类型。在前述的使用流程中,设置模型的输入输出数据类型之时,就需要用到此数据类型的枚举。
| 成员变量名 | 类型 | 值 | 描述 |
|---|---|---|---|
| TYPE_DEFAULT | uint8_t | 0 | 无效的 DataType 类型 |
| TYPE_UINT8 | uint8_t | 1 | 无符号字节数据 |
| TYPE_INT8 | uint8_t | 2 | 字节数据 |
| TYPE_UINT32 | uint8_t | 3 | 无符号 int32 整数 |
| TYPE_FLOAT32 | uint8_t | 4 | Float 数据 |
| TYPE_INT32 | uint8_t | 5 | Int32 数据 |
| TYPE_INT642 | uint8_t | 6 | Int64 数据 |
推理实现类型.enum ImplementType(废除)
| 成员变量名 | 类型 | 值 | 描述 |
|---|---|---|---|
| TYPE_DEFAULT | uint8_t | 0 | 无效 ImplementType 类型 |
| TYPE_MMKV | uint8_t | 1 | 通过 MMKV 实现(现在没有相关的实现,后期可能移除) |
| TYPE_FAST | uint8_t | 2 | 通过 IPC 的后端实现 |
| TYPE_LOCAL | uint8_t | 3 | 通过本地调用的后端实现 |
特别说明:Aidlite-SDK 从 C++ 版本 V2.0.4 开始,将 ImplementType 废除。
模型框架类型.enum FrameworkType
前面提到过,AidliteSDK 整合了多种深度学习推理框架,所以在前述使用流程中,需要设置当前使用哪个框架的模型,就需要使用此框架类型枚举。
| 成员变量名 | 类型 | 值 | 描述 |
|---|---|---|---|
| TYPE_DEFAULT | uint8_t | 0 | 无效 FrameworkType 类型 |
| TYPE_SNPE | uint8_t | 1 | SNPE(dlc) 的模型类型 |
| TYPE_TFLITE | uint8_t | 2 | TFLite 的模型类型 |
| TYPE_RKNN | uint8_t | 3 | RKNN 的模型类型 |
| TYPE_QNN | uint8_t | 4 | QNN 的模型类型 |
| TYPE_SNPE2 | uint8_t | 5 | SNPE2(dlc) 的模型类型 |
| TYPE_NCNN | uint8_t | 6 | NCNN 的模型类型 |
| TYPE_MNN | uint8_t | 7 | MNN 的模型类型 |
| TYPE_TNN | uint8_t | 8 | TNN 的模型类型 |
| TYPE_PADDLE | uint8_t | 9 | Paddle 的模型类型 |
加速硬件类型.enum AccelerateType
对于每个深度学习推理框架而言,可能会支持运行在不同的加速设备上(如 SNPE 模型运行在 DSP 设备,RKNN 模型运行在 NPU 设备),所以在前述使用流程中,需要设置当前模型期望运行在哪个设备,就需要使用此加速硬件枚举。
| 成员变量名 | 类型 | 值 | 描述 |
|---|---|---|---|
| TYPE_DEFAULT | uint8_t | 0 | 无效 AccelerateType 类型 |
| TYPE_CPU | uint8_t | 1 | CPU 加速运行 |
| TYPE_GPU | uint8_t | 2 | GPU 加速运行 |
| TYPE_DSP | uint8_t | 3 | DSP 加速运行 |
| TYPE_NPU | uint8_t | 4 | NPU 加速运行 |
日志级别.enum LogLevel
AidliteSDK 提供有设置日志的接口(后续会介绍),需要提供给接口当前使用哪个日志级别,所以就需要使用此日志级别枚举。
| 成员变量名 | 类型 | 值 | 描述 |
|---|---|---|---|
| INFO | uint8_t | 0 | 消息 |
| WARNING | uint8_t | 1 | 警告 |
| ERROR | uint8_t | 2 | 错误 |
| FATAL | uint8_t | 3 | 致命错误 |
模型类.class Model
前述提到在创建推理解释器之前,需要设置具体模型的相关详细参数。Model 类主要用于记录模型的文件信息、结构信息、运行过程中模型相关内容。
创建实例对象.create_instance()
想要设置模型相关的详细信息,当然就需要先有模型实例对象,此函数用于创建 Model 实例对象。如果模型框架(如 snpe、tflite 等)只需一个模型文件,则调用此接口。
| API | create_instance |
| 描述 | 通过传递模型文件的路径名称,构造 Model 类型的实例对象 |
| 参数 | model_path:模型文件的路径名称 |
| 返回值 | 如果为 nullptr 值,说明函数构建对象失败;否则就是 Mode 对象的指针 |
// 使用当前路径下 inceptionv3_float32.dlc 文件创建模型对象,返回值为空则报错
Model* model = Model::create_instance("./inceptionv3_float32.dlc");
if(model == nullptr){
printf("Create model failed !\n");
return EXIT_FAILURE;
}
创建实例对象.create_instance()
想要设置模型相关的详细信息,当然就需要先有模型实例对象,此函数用于创建 Model 实例对象。如果模型框架(如 ncnn、tnn 等)涉及两个模型文件,则调用此接口。
| API | create_instance |
| 描述 | 通过传递模型文件的路径名称,构造 Model 类型的实例对象 |
| 参数 | model_struct_path:模型结构文件的路径名称 |
| model_weight_path:模型权重参数文件的路径名称 | |
| 返回值 | 如果为 nullptr 值,说明函数构建对象失败;否则就是 Model 对象的指针 |
// 使用当前路径下 ncnn 的两个模型文件创建模型对象,返回值为空则报错
Model* model = Model::create_instance( "./mobilenet_ssd_voc_ncnn.param",
"./mobilenet_ssd_voc_ncnn.bin");
if(model == nullptr){
printf("Create model failed !\n");
return EXIT_FAILURE;
}
设置模型属性.set_model_properties()
模型实例对象创建成功之后,需要设置模型的输入输出数据类型和输入输出 tensor 数据的 shape 信息。
| API | set_model_properties |
| 描述 | 设置模型的属性,输出输出数据 shape 以数据类型 |
| 参数 | input_shapes:输入 tensor 的 shape 数组,二维数组结构 |
| input_data_type:输入 tensor 的数据类型,DataType 枚举类型 | |
| output_shapes:输出 tensor 的 shape 数组,二维数组结构 | |
| output_data_type:输出 tensor 的数据类型,DataType 枚举类型 | |
| 返回值 | void |
// 数据类型使用前述 DataType 枚举,输入输出 shape 是二维数组
std::vector<std::vector<uint32_t>> input_shapes = {{1,299,299,3}};
std::vector<std::vector<uint32_t>> output_shapes = {{1,1001}};
model->set_model_properties(input_shapes, DataType::TYPE_FLOAT32,
output_shapes, DataType::TYPE_FLOAT32);
获取模型路径.get_model_absolute_path()
如果模型框架(如 SNPE、TFLite 等)只涉及一个模型文件,在构建 Model 对象没有异常的情况下,会将传入的模型文件参数转换为绝对路径形式的文件路径。
| API | get_model_absolute_path |
| 描述 | 用于获取模型文件的存在路径 |
| 参数 | void |
| 返回值 | Model 对象所对应的模型文件路径字符串对象 |
获取模型路径.get_model_struct_absolute_path()
如果模型框架(如 NCNN、TNN 等)涉及两个模型文件,在构建 Model 对象没有异常的情况下,会将传入的模型结构文件参数转换为绝对路径形式的文件路径。
| API | get_model_struct_absolute_path |
| 描述 | 用于获取模型结构文件的存在路径 |
| 参数 | void |
| 返回值 | Model 对象所对应的模型结构文件路径字符串对象 |
获取模型路径.get_model_weight_absolute_path()
如果模型框架(如 NCNN、TNN 等)涉及两个模型文件,在构建 Model 对象没有异常的情况下,会将传入的模型权重参数文件参数转换为绝对路径形式的文件路径。
| API | get_model_weight_absolute_path |
| 描述 | 用于获取模型权重参数文件的存在路径 |
| 参数 | void |
| 返回值 | Model 对象所对应的模型权重参数文件路径字符串对象 |
配置类.class Config
前述章节提到在创建推理解释器之前,除了需要设置 Model 具体信息之外,还需要设置一些推理时的配置信息。Config 类用于记录需要预先设置的配置选项,这些配置项在运行时会被用到。
创建实例对象.create_instance()
想要设置运行时的配置信息,当然就需要先有配置实例对象,此函数用于创建 Config 实例对象。
| API | create_instance |
| 描述 | 用于构造 Config 类的实例对象 |
| 参数 | void |
| 返回值 | 如果为 nullptr 值,说明函数构建对象失败;否则就是 Config 对象的指针 |
// 创建配置实例对象,返回值为空则报错
Config* config = Config::create_instance();
if(config == nullptr){
printf("Create config failed !\n");
return EXIT_FAILURE;
}
成员变量列表
Config 对象用于设置运行时的配置信息,其中就包含如下的这些参数:
| 成员变量 | accelerate_type |
| 类型 | enum AccelerateType |
| 默认值 | AccelerateType.TYPE_CPU |
| 描述 | 加速硬件的类型 |
| 成员变量 | implement_type(废除) |
| 类型 | enum ImplementType |
| 默认值 | ImplementType.TYPE_DEFAULT |
| 描述 | 底层功能实现的途径区分 |
特别说明:Aidlite-SDK 从 C++ 版本 V2.0.4 开始,将 ImplementType 废除。
| 成员变量 | framework_type |
| 类型 | enum FrameworkType |
| 默认值 | FrameworkType.TYPE_DEFAULT |
| 描述 | 底层推理框架的类型 |
| 成员变量 | number_of_threads |
| 类型 | int8_t |
| 默认值 | -1 |
| 描述 | 线程数,大于 0 有效 |
| 成员变量 | snpe_out_names |
| 类型 | 字符串数组 |
| 默认值 | 空 |
| 描述 | 模型输出节点的名称列表 for FAST |
| 成员变量 | is_quantify_model |
| 类型 | Int32_t |
| 默认值 | 0 |
| 描述 | 是否为量化模型,1 表示量化模型 for FAST |
| 成员变量 | fast_timeout |
| 类型 | Int32_t |
| 默认值 | -1 |
| 描述 | 接口超时时间(毫秒,大于 0 有效)for FAST |
config->framework_type = FrameworkType::TYPE_SNPE;
config->accelerate_type = AccelerateType::TYPE_CPU;
config->is_quantify_model = 0;
……
Config->snpe_out_names.push_back("InceptionV3/Softmax");
上下文类.class Context
用于存储执行过程中所涉及的运行时上下文,就包括 Model 对象和 Config 对象,后续可能会扩展运行时的数据。
构造函数.Context()
| API | Context |
| 描述 | 构造 Context 实例对象 |
| 参数 | model:Model 实例对象指针 |
| config:Config 实例对象指针 | |
| 返回值 | 正常:Context 实例对象 |
特别说明,参数 model 和 config 两个指针指向的内存空间,必须是堆空间上开辟的。构造 Context 成功之后,它们生命周期将会被 Context 接管( Context 释放时,会自动释放 model 和 config 对象),故而开发者无需再手动释放两者的空间,否则会报错重复释放对象。
获取Model成员变量.get_model()
| API | get_model |
| 描述 | 获取 context 管理的 Model 对象指针 |
| 参数 | void |
| 返回值 | Model 对象的指针 |
获取Config成员变量.get_config()
| API | get_config |
| 描述 | 获取 context 管理的 Config 对象指针 |
| 参数 | void |
| 返回值 | Config 对象的指针 |
解释器类.class Interpreter
Interpreter 类型的对象实例是执行推理操作的主体,用于执行具体的推理过程。前面章节提及的推理流程中,创建解释器对象之后,所有的操作都是基于解释器对象来完成的,所以它是 AidliteADK 绝对的核心内容。
创建实例对象.create_instance()
想要执行推理相关的操作,推理解释器肯定必不可少,此函数就用于构建推理解释器的实例对象。
| API | create_instance |
| 描述 | 利用 Context 对象所管理的各种数据,构造 Interpreter 类型的对象 |
| 参数 | context:Context 实例对象的指针 |
| 返回值 | 为 nullptr 值则说明函数构建对象失败;否则就是 Interpreter 对象的指针 |
// 使用 Context 对象指针来创建解释器对象,返回值为空则报错
Interpreter* current_interpreter = Interpreter::create_instance(context);
if(current_interpreter == nullptr){
printf("Create Interpreter failed !\n");
return EXIT_FAILURE;
}
初始化.init()
解释器对象创建之后,需要执行一些初始化操作(比如环境检查、资源构建等)。
| API | init |
| 描述 | 完成推理所需的相关的初始化工作 |
| 参数 | void |
| 返回值 | 0 值则说明初始化操作执行成功,否则非 0 值就说明执行失败 |
// 解释器初始化,返回值非0则报错
int result = fast_interpreter->init();
if(result != EXIT_SUCCESS){
printf("sample : interpreter->init() failed !\n");
return EXIT_FAILURE;
}
加载模型.load_model()
解释器对象完成初始化操作之后,就可以为解释器加载所需的模型文件,完成模型加载工作。后续的推理过程就使用加载的模型资源。
| API | load_model |
| 描述 | 完成模型加载相关的工作。因为前述在 Model 对象中已经设置模型文件的路径,所以直接执行模型加载操作即可 |
| 参数 | void |
| 返回值 | 0 值则说明模型加载操作执行成功,否则非 0 值就说明执行失败 |
// 解释器加载模型,返回值非0则报错
int result = fast_interpreter->load_model();
if(result != EXIT_SUCCESS){
printf("sample : interpreter->load_model() failed !\n");
return EXIT_FAILURE;
}
设置输入数据.set_input_tensor()
前述章节在介绍流程时提到,设置输入数据之前,对应不同的模型,需要完成不同的前处理操作以适配具体模型。
| API | set_input_tensor |
| 描述 | 设置推理所需的输入 tensor 的数据 |
| 参数 | in_tensor_idx:输入 tensor 的索引值 |
| input_data:输入 tensor 的数据存储地址指针 | |
| 返回值 | 0 值则说明设置输入 Tensor 成功,否则非 0 值就说明执行失败 |
// 设置推理的输入数据,返回值非0则报错
int result = fast_interpreter->set_input_tensor(0,input_tensor_data);
if(result != EXIT_SUCCESS){
printf("interpreter->set_input_tensor() failed !\n");
return EXIT_FAILURE;
}
执行推理.invoke()
前述章节在介绍流程时提到,设置输入数据之后,接下来的步骤自然就是对输入数据执行推理运行过程。
| API | invoke |
| 描述 | 执行推理运算过程 |
| 参数 | void |
| 返回值 | 0 值则说明推理过程执行成功,否则非 0 值就说明执行失败 |
// 执行推理运行操作,返回值非0则报错
int result = fast_interpreter->invoke();
if(result != EXIT_SUCCESS){
printf("sample : interpreter->invoke() failed !\n");
return EXIT_FAILURE;
}
获取输出数据.get_output_tensor()
推理完成之后,就需要将推理得到的结果数据取出来。前述章节在介绍流程时提到,取出结果数据之后,就可以对这些结果数据进行处理,判断结果是否正确。
| API | get_output_tensor |
| 描述 | 推理成功之后,获取推理结果数据 |
| 参数 | out_tensor_idx:结果输出 tensor 的索引值 |
| output_data:该值是指针变量的地址,函数内部重置该指针变量的值 | |
| output_length:该结果输出 tensor 的数据量(字节数) | |
| 返回值 | 0 值则说明获取输出 Tensor 执行成功,否则非 0 值就说明执行失败 |
// 获取推理结果数据,返回值非0则报错
float* out_data = nullptr;
uint32_t output_tensor_length = 0;
int result = fast_interpreter->get_output_tensor(0,
(void**)&out_data, &output_tensor_length);
if(result != EXIT_SUCCESS){
printf("interpreter->get_output_tensor() failed !\n");
return EXIT_FAILURE;
}
资源释放.destory()
前面提到解释器对象需要执行 init() 初始化操作和加载模型的操作,相应的,解释器也会需要执行一些释放操作,将之前创建的资源予以销毁。
| API | destory |
| 描述 | 完成必要的释放操作 |
| 参数 | void |
| 返回值 | 0 值则说明执行释放操作成功,否则非 0 值就说明执行失败 |
// 执行解释器释放过程,返回值非0则报错
int result = fast_interpreter->destory();
if(result != EXIT_SUCCESS){
printf("sample : interpreter-> destory() failed !\n");
return EXIT_FAILURE;
}
解释器创建类.class InterpreterBuilder
统一的解释器 Interpreter 对象的创建函数,通过此类来创建所需的解释器对象。
构建解释器.build_interpretper_from_path()
构建推理解释器对象,可以提供不同的参数,最简单的就是只提供模型文件的路径和名称。如果模型框架(如 SNPE、TFLite 等)只需一个模型文件,则调用此接口。
| API | build_interpretper_from_path |
| 描述 | 通过模型文件的路径名称,直接创建对应的解释器对象 |
| 参数 | path:模型文件的路径名称 |
| 返回值 | 返回值为 Interpreter 类型的 unique_ptr 指针。如果为 nullptr 值,则说明函数构建对象失败;否则就是 Interpreter 对象的指针 |
构建解释器.build_interpretper_from_path()
构建推理解释器对象,可以提供不同的参数,最简单的就是只提供模型文件的路径和名称。如果模型框架(如 NCNN、TNN 等)涉及两个模型文件,则调用此接口。
| API | build_interpretper_from_path |
| 描述 | 通过模型文件的路径名称,直接创建对应的解释器对象 |
| 参数 | model_struct_path:模型结构文件的路径名称 |
| model_weight_path:模型权重参数文件的路径名称 | |
| 返回值 | 返回值为 Interpreter 类型的 unique_ptr 指针。如果为 nullptr 值,则说明函数构建对象失败;否则就是 Interpreter 对象的指针 |
构建解释器.build_interpretper_from_model()
构建推理解释器对象,除了提供模型文件路径之外,也可以提供 Model 对象,这样不仅可以设置模型文件的路径名称,还可以设置模型的输入输出数据类型和输入输出数据的 shape 信息。
| API | build_interpretper_from_model |
| 描述 | 通过传入 Model 对象来创建对应的解释器对象。而 Config 相关涉及的参数都使用默认值 |
| 参数 | model:Model 类型的对象,包含模型相关的数据 |
| 返回值 | 返回值为 Interpreter 类型的 unique_ptr 指针。如果为 nullptr 值,则说明函数构建对象失败;否则就是 Interpreter 对象的指针 |
特别说明,参数 model 指针指向的内存空间,必须是堆空间上开辟的。构造 Interpreter 成功之后,它的生命周期将会被 Interpreter 接管( Interpreter 释放时,会自动释放 model 对象),故而开发者无需再手动释放两者的空间,否则会报错重复释放对象。
构建解释器.build_interpretper_from_model_and_config()
构建推理解释器对象,除了前述的方式,也可以同时提供 Model 对象和 Config 对象,这样不仅可以提供模型相关信息,还可以提供更多的运行时配置参数。
| API | build_interpretper_from_model_and_config |
| 描述 | 通过传入 Model 对象和 Config 来创建对应的解释器对象 |
| 参数 | model:Model 类型的对象,包含模型相关的数据 |
| config:Config 类型的对象,包含一些配置参数 | |
| 返回值 | 返回值为 Interpreter 类型的 unique_ptr 指针。如果为 nullptr 值,则说明函数构建对象失败;否则就是 Interpreter 对象的指针 |
特别说明,参数 model 和 config 两个指针指向的内存空间,必须是堆空间上开辟的。构造 Interpreter 成功之后,它们生命周期将会被 Interpreter 接管( Interpreter 释放时,会自动释放 model 和 config 对象),故而开发者无需再手动释放两者的空间,否则会报错重复释放对象。
// 传入Model和Config对象来构建解释器,返回值为空则报错
std::unique_ptr<Interpreter>&& fast_interpreter =
InterpreterBuilder::build_interpretper_from_model_and_config(model, config);
if(fast_interpreter == nullptr){
printf("build_interpretper failed !\n");
return EXIT_FAILURE;
}
其他方法
Aidlite-SDK 除了提供前述那些推理相关的接口,也提供如下一些辅助接口。
获取SDK版本信息.get_library_version()
| API | get_library_version |
| 描述 | 用于获取当前 aidlite-sdk 的版本相关信息。 |
| 参数 | void |
| 返回值 | 返回值为当前 aidlite-sdk 的版本信息字符串 |
设置日志级别.set_log_level()
| API | set_log_level |
| 描述 | 设置当前的最低日志级别,输出大于等于该日志级别的日志数据。默认打印输出 WARNING 及以上级别的日志 |
| 参数 | log_level:枚举类型 LogLevel 的取值 |
| 返回值 | 默认返回 0 值 |
日志输出到标准终端.log_to_stderr()
| API | log_to_stderr |
| 描述 | 设置日志信息输出到标准错误终端 |
| 参数 | void |
| 返回值 | 默认返回 0 值 |
日志输出到文本文件.log_to_file()
| API | log_to_file |
| 描述 | 设置日志信息输出到指定的文本文件 |
| 参数 | path_and_prefix:日志文件的存放路径与名称前缀 |
| also_to_stderr:标识是否同时输出日志到 stderr 终端,默认值为 false | |
| 返回值 | 0 值则说明执行成功,否则非 0 值就说明执行失败 |
获取最近日志信息.last_log_msg()
| API | last_log_msg |
| 描述 | 获取当前某个日志级别的最新日志信息,通常获取最新的错误信息 |
| 参数 | log_level:枚举类型 LogLevel 的取值 |
| 返回值 | 最新日志信息的存储地址指针 |