AidLite SDK for Android
简介
背景知识
深度学习中最重要的两个基础概念就是模型的 训练 与 推理。
深度学习的“训练”,我们可以把它类比成在学校中学习。你现在想要训练一个能区分苹果还是橘子的模型,你需要搜索一些苹果和橘子的图片,这些图片放在一起称为训练数据集,训练数据集是有标签的,苹果图片的标签就是苹果,橘子亦然。初始的神经网络通过不断的优化自身参数,来让自己变得准确,可能开始 10 张苹果的照片,只有 5 张被神经网络认为是苹果,另外 5 张识别错误,通过优化参数,让另外 5 张错的也变成对的,这个过程就称为训练。
完成训练之后,可以得到实现相关功能的深度学习模型,使用这个模型文件可以实现深度学习的“推理”,即可以基于其训练成果对其所获得的「新数据」进行推导。前述训练好的模型在训练数据集中表现良好,但是我们的期望是它可以对之前没看过的图片进行识别,比如我们重新拍一张包含苹果的图片扔进这个模型,也依然能够正确识别才行。
SDK简介
对于前述的训练和推理两个阶段而言,训练模型需要开发者提前完成,得到可用的算法模型,然后就可以利用这个模型来使用Aidlite-SDK完成推理过程。
aidlite-android(简称Aidlite-SDK)是阿加犀智能科技有限公司封装安卓系统下的AI推理SDK,Aidlite-SDK 是跨平台统一 AI 推理软件开发工具集,针对不同AI框架和不同 AI 芯片的调用进行了抽象,形成统一的 API 接口,可实现模型推理实现的解耦合。 区别于aidlite-c++和aidlite-python,aidlite-android是独立于(Aidlux)平台,安卓开发者需单独集成该SDK在自己应用中。
Aidlite-SDK 针对不同 AI 芯片平台的异构计算资源进行了抽象,实现了不同 AI 芯片厂商异构计算单元调用差异性的无感知化。
- CPU-通用,性能差。
- GPU-差异较少,性能较高。
- NPU-厂商专属,最高性能。
模块化底层封装实现,可快速对新AI框架和新AI芯片进行适配支持,并通过官网下载方式获得更新。
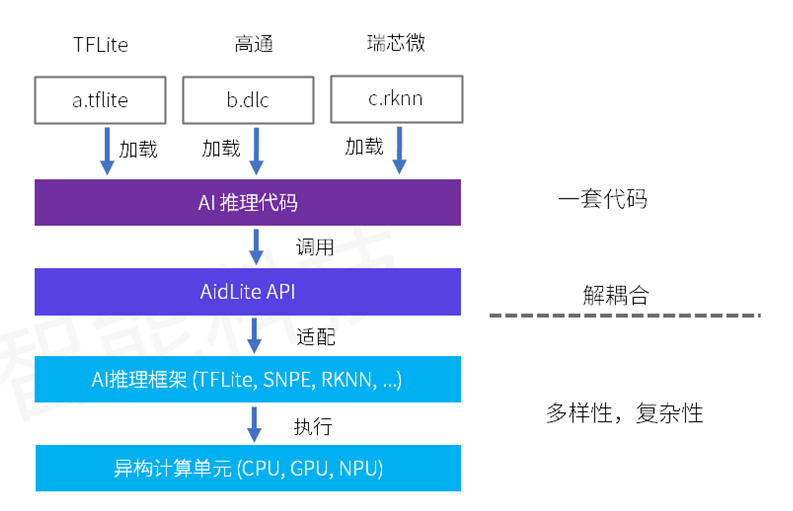
Aidlite-SDK 高度统一的 API 抽象,兼容了不同框架模型及 AI 芯片的调用,让开发人员只需进行一次开发,即可任意更换不同格式的模型或在不同厂商 AI 芯片实现迁移。大大减少了开发者的学习成本,平台迁移难度和成本。摆脱了对特定 AI 框架或者 AI 芯片的绑定,技术选型更灵活,产品落地更快速。
- 兼容主流开源AI框架(TFLITE、ONNX等)。
- 兼容主流AI芯片厂商专属框架(SNPE、RKNN 等),支持厂商专属硬件(NPU)调用。
| Qualcomm SNPE | TFLite | ONNX | RKNN | Paddle Lite | TNN | NCNN | MNN | MindSpore |
|---|---|---|---|---|---|---|---|---|
| ✅ | ✅ | ✅ | ✅ | 🚧 | ⛔ | ⛔ | ⛔ | ⛔ |
✅:已支持 🚧:下版本支持 ⛔:待支持
Aidlite SDK for Android 特性如图所示
![[feature.png]](/en/assets/images/feature-91abfebc14c4671bf88947cea7b81bd3.png)
集成指南
授权信息获取方式
- 使用手机号注册一个AidLux平台账号:AidLux账号注册地址
- 联系我们激活该账号并获取User ID:AidLux商务联系方式
AidLux SDK目前处于内测阶段,暂未开放给所有注册用户使用,需要联系我们激活,注册激活的用户有免费三台设备授权数量
SDK集成步骤
新建project
1.打开Android Studio,在菜单栏中:File->New->New Project,如下图所示
集成配置
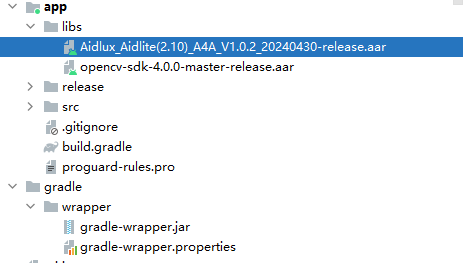
1.导入SDK。在android studio的project视图的主应用app目录下新建libs目录,并将
Aidlux_Aidlite(2.10)_A4A_V1.0.2_20240430-release.aar和opencv-sdk-4.0.0-master-release.aar 同时导入到libs。如图
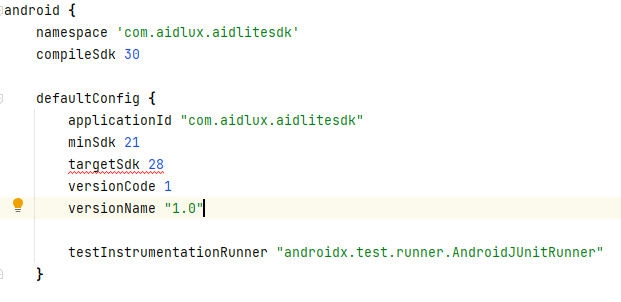
2.配置SDK需要的版本。aidlite-sdk 开发基于compileSdk 30,minSdk 21,targetSdk 28,开发者需保持一致。在主app的build.gradle配置如下
3.添加依赖。在主应用app 目录下的build.gradle的的dependencies下添加依赖
implementation fileTree(include: ['*.jar', "*.aar"], dir: 'libs')
implementation 'com.blankj:utilcodex:1.30.6'
implementation 'net.java.dev.jna:jna:5.10.0'
implementation 'com.elvishew:xlog:1.10.1'
implementation 'com.squareup.retrofit2:retrofit:2.9.0'
implementation 'com.squareup.retrofit2:converter-gson:2.9.0'
implementation 'com.squareup.okhttp3:logging-interceptor:4.9.0'
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.3.9'
4.添加so的打包方式。在主应用app目录下的build.gradle的android的节点范围内添加so的打包方式。
packagingOptions {
jniLibs {
useLegacyPackaging true
}
}
5.申请权限。在AndroidManifest.xml中申请使用SDK必要的权限。
<uses-permission android:name="androidpermissionREAD_PRIVILEGED_PHONE_STATE"/>
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/>
<uses-permission android:name="android.permission.READ_PHONE_STATE" />
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>
<uses-permission android:name="android.permission.INTERNET" />
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
<uses-permission android:name="android.permission.MANAGE_EXTERNAL_STORAGE" />
开发流程
Aidlite-SDK 在底层整合了多种深度学习的推理框架,所以不管具体使用的是哪个深度学习框架的模型,其推理所需流程、所需 API 都是高度统一的。
前置准备
Aidlite SDK for Android 是用来完成深度学习推理过程的组件,需要用到已经完成训练的深度学习算法模型,所以在使用此 SDK 之前,需要有某个深度学习框架(如 SNPE、TFLite 等)的训练好的模型文件。
Aidlite SDK for Android是基于Android环境下的AI推理SDK,搭配模型转换平台AIMO,可以帮助开发者快速将现有模型迁移部署至终端设备。
-
Aidlite SDK for Android下载链接 (SNPE对应版本请参考AidliteSDK版本支持矩阵):
-
Aidlite SDK for Android详细的接口介绍及说明请参考:AidliteSDK (Android) API文档
-
AIMO在线访问链接:AI模型优化平台
一般流程
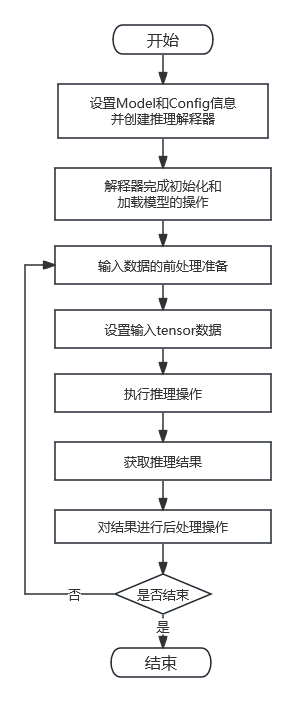
对于Android SDK for Android完整的推理流程,一般需要经过如下所示的几个步骤:
- 对SDK进行初始化,主要是保证SDK被授权,推理组件正常运行,SDK日志开启等。这个一般在应用程序启动的时候初始化一次就行。
- 设置模型相关的参数,告知推理组件这个模型的详细信息,在推理过程中会使用到这些参数以更好地完成推理工作。
- 参数配置完成之后,使用这些参数生成推理解释器,并完成解释器的初始化。
- 完成模型的加载过程(加载过程的耗时长短不定)。
- 对输入数据做一些前处理操作(比如求均值方差、转为 float 数据类型等),得到模型推理所需的数据。
- 推理解释器设置输入数据。
- 使用推理解释器完成推理过程。
- 取出推理完成后的结果数据。
- 对于结果数据,做一些相关的后处理操作(比如找出置信度最高的分类等),得出结果。
通常来说,推理的实现过程是为模型提供不同的输入数据,然后在推理之后得到不同的输出数据,并解析输出数据看结果是否正常。所以对于相同的模型,上述第 5、6、7、8、9 步骤是持续循环执行的过程,而在此之前的步骤仅需执行一次。
差异操作
对于区别于aidlite-c++和aidlite-python,aidlite-android 需要对SDK 进行初始化。
另外,在上述的统一流程中,针对不同框架的不同模型文件,也会有些具体的差异:
- 前述第 2 步骤,对于不同模型,需要不同的 Model 对象和 Config 对象的配置(如模型类型、模型输入输出数据类型等),用以告知 Aidlite-SDK 该模型相关的详细信息。
- 前述第 5 步骤,对于不同模型,需要不同的输入数据,也就有不同的前处理操作。
- 前述第 9 步骤,对于不同模型,会有不同的结果数据,也就有不同的后处理操作。
开发流程图
推理流程如下图所示。
AidSDK for Android 完整示例演示
// --------------------0. AidSDK authorization and initialization------------------ //
Aidlite.INSTANCE.initialize(getApplication(), "your user id", true);
// --------------------1. Initialize AidSDK interpreter------------------ //
// initialize Model Class
Model model = new Model(modelFileAbsoluteFilePath);
// initialize Config Class for inference configuration // set inference unit as DSP
Config config = new Config(AccelerateType.TYPE_NPU);
//set Inference Framework ,example for SNPE
config.setFrameworkType(FrameworkType.TYPE_SNPE);
// build a Interpreter Class by model and config
Interpreter interpreter = new Interpreter.Builder().build(getApplication(), model, config);
// initialize interpreter
int initInterpreterRet = interpreter.init();
// --------------------2. Load model by interpreter------------------ //
// load model
int loadModelRet = interpreter.loadModel();
// --------------------3. Initialize DataWrapper and set input ------------------ //
// initialize DataWrapper and set tensor type to FP32
DataWrapper dataWrapper = new DataWrapper(TensorType.FLOAT32);
// input data into dataWrapper
dataWrapper.setFloats(inputData);
// set first (index = 0) input data into interpreter, this model only have one input
interpreter.setInputTensor(0,dataWrapper);
// --------------------4. Invoke ------------------ //
// invoke
int invokeRet = interpreter.invoke();
// --------------------5. Get output from DataWrapper ------------------ //
// get first(index = 0) output from interpreter
DataWrapper outputTensor = interpreter.getOutputTensor(0);
// --------------------6. Release interpreter ------------------
interpreter.release();
特别说明
针对SNPE模型
版本区分
Aidlite SDK for Android内置了编译好的SNPE Runtime,针对不同的硬件设备,SNPE Runtime被区分为两个版本:
- Aidlite(1.61) SDK for Android:针对SM8250及以下的机型(通常针对大多数已往的硬件设备)
- Aidlite(2.10) SDK for Android:针对QCM6490及以上的机型(针对高通较新的硬件设备,特别是有QNN架构的设备)
版本支持矩阵
| Snapdragon Device/Chip | Aidlite(1.61) SDK for Android | Aidlite(2.10) SDK for Android |
|---|---|---|
| SD 8 Gen 3 (SM8650) | No | Yes |
| SD 8 Gen 2 (SM8550) | No | Yes |
| SD 8+ Gen 1 (SM8475) | No | Yes |
| SD 8 Gen 1 (SM8450) | No | Yes |
| SD 8 Gen 1 (SM8450) | No | Yes |
| 888+ (SM8350P) | No | Yes |
| 888 (SM8350) | No | Yes |
| 7 Gen 1 (SM7450) | No | Yes |
| 778G (SM7325) | No | Yes |
| QCM6490 | No | Yes |
| 865 (SM8250) | Yes | No |
| QCM6490 | Yes | No |
| 765 (SM7250) | Yes | No |
| 750G (SM7225) | Yes | No |
| 690 (SM6350) | Yes | No |
| QRB5165U | Yes | No |
| QRB5165LE | Yes | No |
| QCS7230LE | Yes | No |
| 695 (SM6375) | Yes | No |
| 680 (SM6225) | Yes | No |
| 480 (SM4350/6325) | Yes | No |
| 460 (SM4250) | Yes | No |
| 662 (SM6115) | Yes | No |
| QCS610LA | Yes | No |
| QCS610LE | Yes | No |
| QCS410LA | Yes | No |
| QCS410LE | Yes | No |
| QCM4290 | Yes | No |
| QCM6125 | Yes | No |
| 480 (SM4350/6325) | Yes | No |
| QRB4210LE | Yes | No |
| QCM4490 | Yes | No |
开发者在下载Aidlite SDK的时候请根据自身硬件情况下载对应的SDK版本,如果通过AIMO获取Aidlite SDK则不需要关心版本问题,AIMO会自动匹配合适的Aidlite SDK版本
关于SNPE版本介绍请参考:SNPE Release Notes
量化与反量化
!> 反量化操作仅针对Aidlite(2.10)SDK for Android版本量化模型,并且是推理使用的NPU进行推理。Aidlite(1.61)SDK不需要此操作
Aidlite(1.61)SDK版本步骤6中get output会获得反量化之后的float值,开发者进行后续后处理即可
Aidlite(2.10)SDK版本步骤6中get output会获得量化结果(但以float格式返回),开发者需要自行进行反量化,反量化操作如下:
- 编写反量化函数,反量化公式为:
dequantization = min + quantization * scale
或者
dequantization = (quantization+offset) * scale
/**
* dequantilize int to float
* @param quantilizedArray
* @param scale
* @param min
* @return void
*/public static void dequantilize(float[] quantilizedArray, float scale, float min) {
for (int i=0; i<quantilizedArray.length; i++) {
quantilizedArray[i] = min + quantilizedArray[i] * scale;
}
}
或者
/**
* dequantilize int to float
* @param quantilizedArray
* @param scale
* @param offset
* @return void
*/public static void dequantilize(float[] quantilizedArray, float scale, float offset) {
for (int i=0; i<quantilizedArray.length; i++) {
quantilizedArray[i] = (quantilizedArray[i] + offset)* scale;
}
}
-
查看模型结构文件(可以使用Netron查看,也可用转换结果自带的html文件查看)
-
获取$min$,$scale$,$offset$的值(通过html文件从模型结构输出节点处获取)
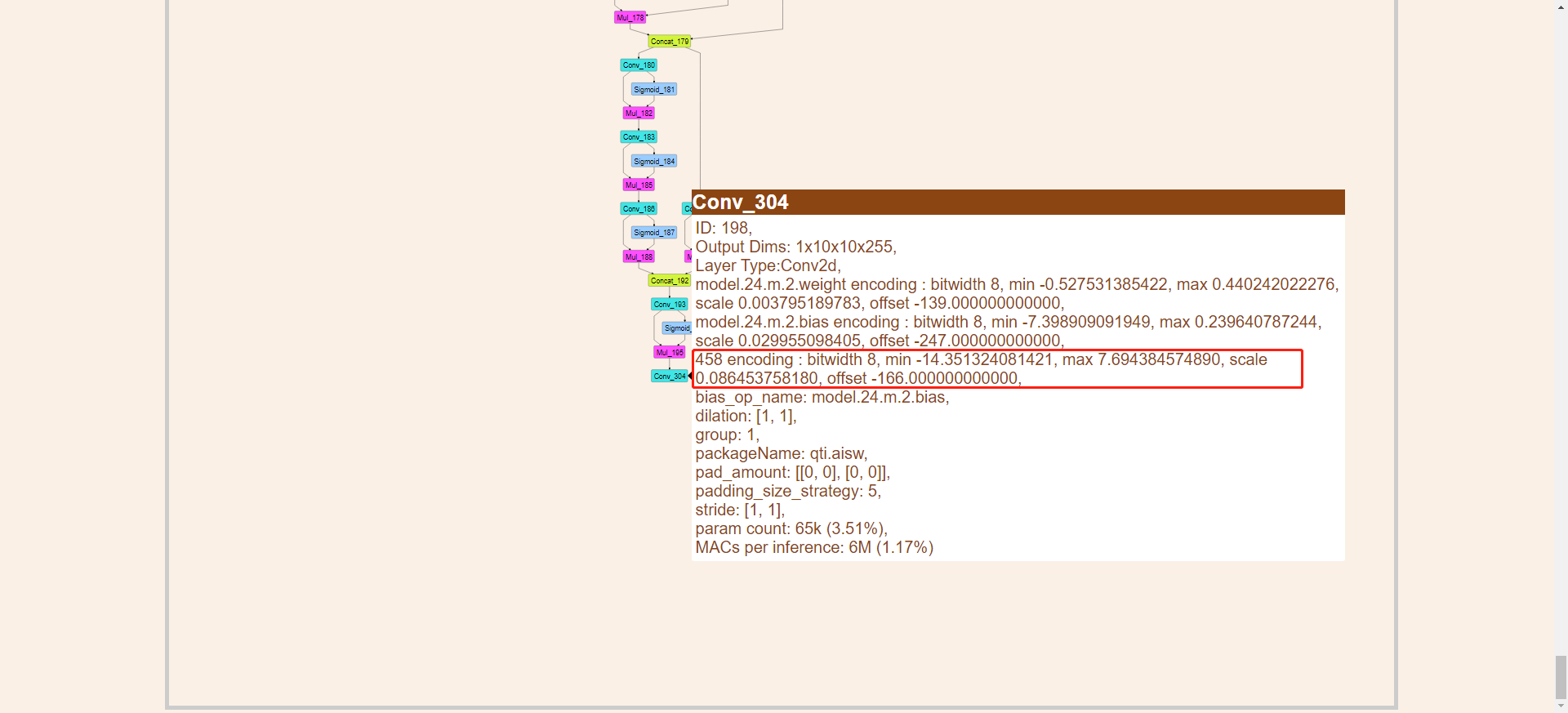
-
直接用SDK工具类对每个输出都进行反量化
aidUtil.dequantilize(outputTensor0.floats, -174f, 0.139637455344.toFloat()) //model.24/m.2/Conv
aidUtil.dequantilize(outputTensor1.floats, -185f, 0.162173867226.toFloat()) ///model.24/m.1/Conv
aidUtil.dequantilize(outputTensor2.floats, -182f, 0.138708263636.toFloat()) //model.24/m.0/Conv
接口详细说明
模型数据类型.enum TensorType
对于 Aidlite SDK for Android 而言,会处理不同框架的不同模型,每个模型自己也有不同的输入数据类型和不同的输出数据类型。在前述的使用流程中,设置模型的输入输出数据类型之时,就需要用到此数据类型的枚举。
| 成员变量名 | 类型 | 值 | 描述 |
|---|---|---|---|
| INT8 | int | 0 | 字节数据 |
| FLOAT32 | int | 1 | Float 数据 |
| Int64 | int | 2 | Int64 数据 |
模型框架类型.enum FrameworkType
前面提到过,AidliteSDK 整合了多种深度学习推理框架,所以在前述使用流程中,需要设置当前使用哪个框架的模型,就需要使用此框架类型枚举。
| 成员变量名 | 类型 | 值 | 描述 |
|---|---|---|---|
| TYPE_TFLITE | int | 0 | TFLite 的模型类型 |
| TYPE_SNPE | int | 1 | SNPE(DLC) 的模型类型 |
| TYPE_ONNX | int | 2 | ONNX 的模型类型 |
| TYPE_RKNN | int | 3 | RKNN 的模型类型 |
| TYPE_NCNN | int | 4 | NCNN 的模型类型 |
| TYPE_MNN | int | 5 | MNN 的模型类型 |
| TYPE_TNN | int | 6 | TNN 的模型类型 |
| TYPE_PADDLE | int | 7 | Paddle 的模型类型 |
加速硬件类型.enum AccelerateType
对于每个深度学习推理框架而言,可能会支持运行在不同的加速设备上(如 SNPE 模型运行在 DSP 设备,RKNN 模型运行在 NPU 设备),所以在前述使用流程中,需要设置当前模型期望运行在哪个设备,就需要使用此加速硬件枚举。
| 成员变量名 | 类型 | 值 | 描述 |
|---|---|---|---|
| TYPE_CPU | int | 1 | CPU 加速运行 |
| TYPE_GPU | int | 2 | GPU 加速运行 |
| TYPE_NPU | int | 3 | NPU 加速运行 |
SDK授权,日志初始化等管理类.class Aidlite
前述提到Aidlite SDK for Android区别于aidlite-c++、aidlite-python,在使用该SDK进行推理之前需要对SDK进行授权。Aidlite类就是负责对SDK进行授权,控制SDK日志级别输出.
Public Member Functions
public boolean initialize(Application mApplication,String userId,boolean logDebug)
描述:Aidlite对SDK进行初始化,授权,建议在Application中调用。
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| mApplication | Application | - | 上下文 |
| userId | String | - | 开发者的用户id |
| logDebug | boolean | - | 控制SDK日志级别的开关,为true, sdk会打印所有级别的日志,为false,只会打印error级别的日志 |
- 返回
| 类型 | 描述 |
|---|---|
| boolean | sdk初始化成功与否的标志,为true表示初始化成功,false失败 |
boolean initializeRet = Aidlite.INSTANCE.initialize(getApplication(), "uSD8go3tWsrev+Lb*******", false);
if (initializeRet){
//SDK's initialization is successful
}else {
//SDK's initialization is fail
}
模型类.class Model
前述提到在创建推理解释器之前,需要设置具体模型的相关详细参数。Model 类主要用于记录模型的文件信息、结构信息、运行过程中模型相关内容。
Public Member Functions
public Model (String modelAbsolutePath);
描述:通过传递模型文件的绝对路径名称,构造Model类型的对象。参数说明如下:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| modelAbsolutePath | String | - | 模型文件的路径名称 |
// initialize Model Class
Model model = new Model(modelFileAbsoluteFilePath);
public Model (String modelAbsolutePath,String key);
描述:通过传递加密模型文件的绝对路径名称,解密的密钥key,构造Model类型的对象。参数说明如下:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| modelAbsolutePath | String | - | 加密模型文件的路径名称 |
| key | String | - | 解密的密钥key |
// initialize Model Class
String decryModelKey="NDd0Kk00TE1qZmJeZTZIUExRMm***************"
Model model = new Model(modelFileAbsoluteFilePath,decryModelKey);
public void setInputType(TensorType inputType)
描述:设置模型的输入类型。如前述提到,不同框架的不同模型的输入类型有int8,fp32,int64等
- 参数
通过传递模型输入的类型。参数说明如下:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| inputType | TensorType | - | 模型的输入数据类型,枚举类型 |
- 返回 无
示例代码:
// initialize Model Class
Model model = new Model(modelFileAbsoluteFilePath);
model.setInputType(TensorType.INT8)
public TensorType getInputType()
描述:获取已经设置的模型输入类型
- 参数 无
- 返回
| 类型 | 描述 |
|---|---|
| TensorType | 模型的输入数据类型,枚举类型 |
示例代码:
// initialize Model Class
Model model = new Model(modelFileAbsoluteFilePath);
TensorType inputTensorType= model.getInputType()
public void setOutputType(TensorType outputType)
描述:设置模型的输出类型。如前述提到,不同框架的不同模型的输出类型有int8,fp32,int64等
通过传递模型输出的类型。参数说明如下:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| outputType | TensorType | - | 模型的输出数据类型,枚举类型 |
示例代码:
// initialize Model Class
Model model = new Model(modelFileAbsoluteFilePath);
model.setOutputType(TensorType.FLOAT32)
public TensorType getOutputType()
描述:获取已经设置的模型输出类型。
- 参数 无
- 返回
| 类型 | 描述 |
|---|---|
| TensorType | 模型的输出数据类型,枚举类型 |
示例代码:
// initialize Model Class
Model model = new Model(modelFileAbsoluteFilePath);
TensorType inputTensorType= model.getOutputType()
public void setInputShapes(long[][] inShape)
描述:该方法设置模型的输入张量的shape信息,比如NCHW,1*3*320*320或者NHWC,1*320*320*3模型的单输入或是多输入
- 参数
通过传递模型输入shape。参数说明如下:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| inputShapes | long[][] | - | 输入tensor的shape数组 二维数组结构:: |
- 返回 无
示例代码:
// initialize Model Class
Model model = new Model(modelFileAbsoluteFilePath);
//init model input shapes for single input
long[][] inputShapes = new long[1][4];
//init single input for NHWC
long[] oneInputShapes = {1,320,320,3};
inputShapes[0]=oneInputShapes;
model.setInputShapes(inputShapes);
public long[][] getInputShapes()
描述:获取已设置的模型输入shapes
- 参数 无
- 返回
| 类型 | 描述 |
|---|---|
| long[][] | 输入tensor的shape数组 二维数组结构 |
public void setOutputShapes(long[][] shapes)
描述:设置模型的输出shapes。
- 参数
通过传递模型输入shape。参数说明如下:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| outShape | long[][] | - | 输出tensor的shape数组 二维数组结构: |
- 返回 无
public long[][] getOutputShapes()
描述:获取设置的模型的输出shapes。
- 参数 无
- 返回
| 类型 | 描述 |
|---|---|
| long[][] | 输出tensor的shape数组 二维数组结构 |
public void setKey(String key)
描述:设置解密解密的密钥key,针对模型是加密模型,如果模型是直接可以打开,未加密的,不用设置
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| key | String | - | 解密的密钥key |
- 返回 无
示例代码:
String decryModelKey="NDd0Kk00TE1qZmJeZTZIUExRMm***************"
// initialize Model Class
Model model = new Model(modelFileAbsoluteFilePath);
model.setKey(decryModelKey)
public String getModelAbsolutePath()
描述:获取模型的文件的全路径
- 参数 无
- 返回
| 类型 | 描述 |
|---|---|
| String | 模型文件的路径名称 |
配置类.class Config
前述章节提到在创建推理解释器之前,除了需要设置 Model 具体信息之外,还需要设置一些推理时的配置信息。Config 类用于记录需要预先设置的配置选项,这些配置项在运行时会被用到。
Public Member Variables
| 成员变量名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| accelerateType | AccelerateType | AccelerateType.TYPE_CPU | 推理的计算单元,有CPU,GPU,NPU |
| frameworkType | FrameworkType | FrameworkType.TYPE_SNPE | 深度学习框架的类型,比如.dlc模型就是TYPE_SNPE,.tflite就是TYPE_TFLITE |
| numberOfThreads | int | 1 | 线程数量,仅部分框架需要 |
| outNodes | String[] | null | 模型的输出节点,仅部分框架需要指定,例如目前dlc模型 |
| isQuantifyModel | 是否是量化模型 | 0 | 模型是否量化模型Int8,仅部分框架需要设置该字段,例如目前dlc模型 |
上述表格目前仅列出少部分的成本变量,后续会随着开发的深入逐步增多。
Public Member Functions
构造函数 public Config(AccelerateType accelerateType)
描述:用于构造Config对象。
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| accelerateType | AccelerateType | - | 模型推理的时,所使用的推理计算单元,CPU,GPU or NPU |
示例代码:
// initialize Config Class for inference configuration and set inference unit as DSP
Config config = new Config(AccelerateType.TYPE_NPU);
public AccelerateType getAccelerateType()
描述:获取设置的推理计算单元
- 参数
无
- 返回
| 类型 | 描述 |
|---|---|
| AccelerateType | 推理该模型的计算单元 |
public void setFrameworkType(FrameworkType frameworkType)
描述:如前章所属,用户需要设置模型的框架类型,方便后续加载模型,推理时使用。比如qualcomm snpe的dlc模型,FrameworkType.TYPE_SNPE
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| frameworkType | FrameworkType | - | 深度学习框架的类型 |
- 返回 无
示例代码:
// initialize Config Class for inference configuration and set inference unit as DSP
Config config = new Config(AccelerateType.TYPE_NPU);
config.setFrameworkType(FrameworkType.TYPE_SNPE)
public FrameworkType getFrameworkType()
描述:获取已经设置的深度学习框架类型
- 参数
无
- 返回
| 类型 | 描述 |
|---|---|
| FrameworkType | 深度学习框架的类型 |
public void setNumberOfThreads(int numberOfThreads)
描述:当设置推理计算单元为CPU时,可以设置该方法,让CPU在推理时执行几个线程推理。
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| numberOfThreads | int | - | 在使用CPU推理时用到的线程数量,仅部分框架可选指定,例如当前tflite框架 |
- 返回 无
示例代码:
// initialize Config Class for inference configuration and set inference unit as DSP
Config config = new Config(AccelerateType.TYPE_CPU);
config.setNumberOfThreads(4);
public int getNumberOfThreads()
描述:获取先前设置的CPU推理时,推理线程数量。
- 参数
无
- 返回
| 类型 | 描述 |
|---|---|
| int | 推理时用到的线程数量 |
public void setOutNodes(String[] outNodes)
描述:如前章所述对于多输出的模型,部分推理框架需要指定输出节点。例如框架是SNPE框架(DLC模型)
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| outNodes | String[] | - | 模型的输出节点,仅部分框架需要 |
- 返回 无
示例代码:
// initialize Config Class for inference configuration and set inference unit as DSP
Config config = new Config(AccelerateType.TYPE_NPU);
config.setFrameworkType(FrameworkType.TYPE_SNPE);
//"Conv_304", "Conv_250", "Conv_196" Each output node name of the three outputs model
config.setOutNodes(new String[]{"Conv_304", "Conv_250", "Conv_196"});
public String[] getOutNodes()
描述:获取已经设置的多输出节点名。
- 参数
无
- 返回
| 类型 | 描述 |
|---|---|
| String[] | 给模型设置的输出节点 |
public void setIsQuantifyModel(int isQuantifyModel)
描述:模型是否是量化模型。如果使用厂商自带的NPU计算单元推理时,则模型为量化模型。
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| isQuantifyModel | int | 0 | 当前模型是否是量化int8模型,0:非量化 1:量化 |
- 返回 无
// initialize Config Class for inference configuration and set inference unit as DSP
Config config = new Config(AccelerateType.TYPE_NPU);
//model is quantified
config.setIsQuantifyModel(1);
public int getIsQuantifyModel()
描述:获取模型是否是量化模型
- 参数
无
- 返回
| 类型 | 描述 |
|---|---|
| int | 当前模型是否是量化int8模型,0:非量化 1:量化 |
推理主类.class Interpreter
该类的对象是执行推理操作的解释器主体,用于执行相应的执行推理的过程。
Public Member Functions
public int init()
描述:完成推理所需的初始化相关工作。
- 参数
无
- 返回
| 类型 | 描述 |
|---|---|
| int | 解释器初始化的结果0:成功,-1:失败 |
示例代码:
// initialize interpreter
int initInterpreterRet = interpreter.init();
if (initInterpreterRet == 0) {
Log.i("AidSDKSample", "Initialize Interpreter success!");
} else {
Log.i("AidSDKSample", "Initialize Interpreter failed!");
}
public int loadModel();
描述:在执行模型进行推理之前,需要将模型文件加载到内存中,完成模型加载相关的工作。因为在Model对象中已经设置了模型文件的路径,所以直接加载模型即可。
- 参数
无
- 返回
| 类型 | 描述 |
|---|---|
| int | 解释器加载模型的结果 0:成功,-1:失败 |
示例代码:
// --------------------3. Load model by interpreter------------------ //
// load model
int loadModelRet = interpreter.loadModel();
if (loadModelRet == 0) {
Log.i("AidSDKSample", "Load model success!");
} else {
Log.i("AidSDKSample", "Load model failed!");
}
public int setInputTensor(int tensorIndex,DataWrapper dataWrapper)
描述:设置模型推理数据。
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| tensorIndex | Int | - | 输入tensor的索引值 |
| dataWrapper | DataWrapper | - | 输入tensor的数据存储类 |
- 返回
| 类型 | 描述 |
|---|---|
| int | 解释器设置张量输入的返回结果 0:成功,-1:失败 |
示例代码:
// --------------------4. Initialize DataWrapper and set input ------------------ //
// initialize DataWrapper and set tensor type to FP32
DataWrapper dataWrapper = new DataWrapper(TensorType.FLOAT32);
// input data into dataWrapper
dataWrapper.setFloats(floats);
// set first (index = 0) input data into interpreter, this model only have one input
interpreter.setInputTensor(0, dataWrapper);
public int invoke()
描述:对前几步完成之后,进行推理。
- 参数 无
- 返回
| 类型 | 描述 |
|---|---|
| int | 解释器进行推理 返回值 0:推理成功,-1:推理失败 |
// --------------------5. Invoke ------------------ //
int invokeRet = interpreter.invoke();
if (invokeRet == 0) {
Log.i("AidSDKSample", "Invoke success!");
} else {
Log.i("AidSDKSample", "Invoke failed!");
}
public DataWrapper getOutputTensor(int tensorIndex)
描述:推理完成之后,如果推理成功。获取推理结果数据。
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| tensorIndex | Int | - | 输出tensor的索引值 |
- 返回
| 类型 | 描述 |
|---|---|
| DataWrapper | 推理后获取的结果数据 |
示例代码:
// --------------------6. Get output from DataWrapper ------------------ //
DataWrapper outputTensor0 = interpreter.getOutputTensor(0); //conv_196
DataWrapper outputTensor1 = interpreter.getOutputTensor(1); //conv_304
DataWrapper outputTensor2 = interpreter.getOutputTensor(2); //conv_250
public int release()
描述:如果推理完之后,后续不在进行该interpreter进行后续推理,可以进行推理相关的释放。如果还需要持续推理,则不能释放。建议将释放操作放到activity的onDestroy()中。
- 参数 无
- 返回
| 类型 | 描述 |
|---|---|
| int | 解释器进行资源释放 0:释放成功 其他:释放失败 |
示例代码:
// --------------------7. Release interpreter ------------------
interpreter.release();
if (releaseRet==0){
//release successfully
}else {
//release fail
}
class Interpreter.Builder
统一的解释器 Interpreter 对象构造者,通过此类来构造所需的解释器对象。
Public Member Functions
public Interpreter build(Application appplication , String modelAbsolutePath)
描述:通过上下文和模型文件的绝对路径名称,构造对应的解释器对象。
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| appplication | Application | - | 应用的application实例 |
| modelAbsolutePath | String | - | 推理模型的路径 |
- 返回
| 类型 | 描述 |
|---|---|
| Interpreter | 解释器实例对象 |
示例代码:
// build a Interpreter Class by model absolute path
Interpreter interpreter = new Interpreter.Builder().build(getApplication(), modelFileAbsoluteFilePath);
public Interpreter build(Application appplication ,Model model)
描述:通过上下文和已经创建好的模型对象,构造对应的解释器对象。
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| appplication | Application | - | 应用的application实例 |
| model | Model | - | 推理的模型 |
- 返回
| 类型 | 描述 |
|---|---|
| Interpreter | 解释器实例对象 |
示例代码:
// build a Interpreter Class by model
Interpreter interpreter = new Interpreter.Builder().build(getApplication(), model);
public Interpreter build(Application appplication ,Model model ,Config config )
描述:通过出入Model对象和Config对象来构造对应的解释器。在此之前,调用者可以自主设置Model和Config相关的各项参数。
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| appplication | Application | - | 应用的application实例 |
| model | Model | - | 推理的模型 |
| config | Config | - | 推理模型的相关配置 |
- 返回
| 类型 | 描述 |
|---|---|
| Interpreter | 解释器实例对象 |
示例代码:
Model model =new Model(modelFileAbsoluteFilePath)
model.outputShapes = twoDimensionalArray
Config config =new Config(AccelerateType.TYPE_NPU)
Interpreter interpreter = Interpreter.Builder().build(application, model, config)
class DataWrapper
Public Member Functions
public DataWrapper(TensorType tensorType)
描述:专门用于存储向模型传递数据的封装类
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| tensorType | TensorType | - | 传递数据的类型 |
public TensorType getTensorType()
描述:获取传递数据的张量数据类型
- 参数
无
- 返回
| 类型 | 描述 |
|---|---|
| TensorType | 张量数据类型 |
public void setTensorType(TensorType tensorType)
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| tensorType | TensorType | - | 张量数据类型 |
- 返回 无
public float[] getFloats()
描述:根据TensorType,如果DataWrapper的TensorType为FLOAT32,或者如前章所属,在初始化Model的时候会设定模型的输出类型。
-
参数 无
-
返回
| 类型 | 描述 |
|---|---|
| float[] | 返回float数组 |
示例代码:
// --------------------6. Get output from DataWrapper ------------------ //
DataWrapper dataWrapper0 = interpreter.getOutputTensor(0); //conv_196
DataWrapper dataWrapper1 = interpreter.getOutputTensor(1); //conv_304
DataWrapper dataWrapper2 = interpreter.getOutputTensor(2); //conv_250
if (dataWrapper0.getTensorType()==TensorType.FLOAT32){
float[] floats0 = dataWrapper0.getFloats();
}
if (dataWrapper1.getTensorType()==TensorType.FLOAT32){
float[] floats1 = dataWrapper1.getFloats();
}
if (dataWrapper2.getTensorType()==TensorType.FLOAT32){
float[] floats2 = dataWrapper2.getFloats();
}
// dequantilize output, just operator for SNPE2.10 and NPU inference。
public void setFloats(float[] floats)
描述:在推理之前,需要设置数据给DataWrapper。 当模型的输入是TensorType为FLOAT32,需要设置floats数据
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| floats | float[] | - | 设置的输入的float数组 |
- 返回 无
示例代码:
// --------------------4. Initialize DataWrapper and set input ------------------ //
// initialize DataWrapper and set tensor type to FP32
DataWrapper dataWrapper = new DataWrapper(TensorType.FLOAT32);
// input data into dataWrapper
dataWrapper.setFloats(floats);
public byte[] getBytes()
描述:根据TensorType,如果DataWrapper的TensorType为INT8,或者如前章所属,在初始化Model的时候会设定模型的输出类型。
-
参数 无
-
返回
| 类型 | 描述 |
|---|---|
| byte[] | 返回byte数组 |
public void setBytes(byte[] bytes)
描述:在推理之前,需要设置数据给DataWrapper。 当模型的输入是TensorType为INT8,需要设置bytes数据
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| bytes | byte[] | - | 设置的输入的byte数组 |
- 返回 无
示例代码:
// --------------------4. Initialize DataWrapper and set input ------------------ //
// initialize DataWrapper and set tensor type to INT8
DataWrapper dataWrapper =new DataWrapper(TensorType.INT8);
dataWrapper.setByts(bytes);
interpreter.setInputTensor(0,dataWrapper);
class BindToCpu
该类属于推理提供的友好工具类,用于开发者绑定cpu核心,来提高CPU的使用率。
Public Member Functions
public static void cpuBind(int cpu)
描述:
- 参数
通过传递模型输入的类型。参数说明如下:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| cpu | int | - | 要绑定到哪个cpu核上执行 |
- 返回 无
public static void cpuUnbind(int cpu)
描述:用于开发者在绑核之后,执行完代码,解绑。
- 参数
通过传递模型输入的类型。参数说明如下:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| cpu | int | - | 要解绑在哪个cpu核上执行 |
- 返回 无
public static int getCores()
描述:获取CPU的核数。
- 参数 无
- 返回
| 类型 | 描述 |
|---|---|
| int | 返回SOC的CPU数量 |
工具类.class AidUtil
此类为开发者提供的友好工具类。提供了友好工具函数,比如图片的等比缩放,缩放,以及高性能,低耗时的数据转换处理,比如安卓中常用的Camera的数据YUVI420_888和NV21,NV12,RGB24,bitmap,image之间的转换,缩放,裁剪等。
Public Member Functions
public Bitmap resizeProportionally(Bitmap srcBitmap,int targetWidth,int targetHeight,int interpolation)
描述:图片进行等比缩放。比如一些模型的预处理,需要对图片进行直接缩放。
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| srcBitmap | Bitmap | - | 原始图片 |
| targetWidth | int | - | 目标宽 |
| targetHeight | int | - | 目标高 |
| interpolation | int | Imgproc.INTER_LINEAR 线性插值 | 插值方式 |
- 返回
| 类型 | 描述 |
|---|---|
| Bitmap | 原图经过等比缩放后的bitmap |
// ------------------------------1. Preprocess------------------------------ //
// resize: bitmap - bitmap
Bitmap resizedBitmap = aidUtil.resizeProportionally(imageBitmap, inputShape, inputShape)
public Bitmap resize(Bitmap srcBitmap,int targetWidth,int targetHeight,int interpolation)
图片进行缩放,但不一定等比
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| srcBitmap | Bitmap | - | 原始图片 |
| targetWidth | int | - | 目标宽 |
| targetHeight | int | - | 目标高 |
| interpolation | int | Imgproc.INTER_LINEAR 线性插值 | 插值方式 |
- 返回
| 类型 | 描述 |
|---|---|
| Bitmap | 原图经过缩放后的bitmap |
public void dequantilize(float[] quantilizedArray,float offset,float scale)
描述:如前章所述,对snpe2.10 (dlc模型),进行对量化模型,npu推理时,输出需要手动反量化。这里提供友好工具函数,用户直接可以调用。调用之后,反量化的数据直接存储在quantilizedArray中
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| quantilizedArray | float[] | - | 获取需要反量化的float数组,针对dlc量化模型,并使用dsp推理 |
| offset | float | - | 模型当前输出节点的反量化参数offset |
| scale | float | - | 模型当前输出节点的反量化参数scale |
- 返回 无
示例代码:
// dequantilize output, special operator of dlc 2.10 and NPU inference
aidUtil.dequantilize(outputTensor0.floats, - 174f, 0.139637455344.toFloat(),) ///model.24/m.2/Conv
aidUtil.dequantilize(outputTensor1.floats, -185f, 0.162173867226.toFloat()) ///model.24/m.1/Conv
aidUtil.dequantilize(outputTensor2.floats, -182f, 0.138708263636.toFloat()) ///model.24/m.0/Conv
public void yuvNV21ToI420(byte[] nv21,int width,int height,byte[] i420Dst)
描述:高效的对yuvNV21转I420,主要用于对YUV数据转换。
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| nv21 | byte[] | - | yuvnv21格式的byte数组 |
| width | int | - | 图像的宽度 |
| height | int | - | 图像的高度 |
| i420Dst | byte[] | - | 转换后的yuvI420数据 |
- 返回 无
aidUtil.yuvNV21ToI420(NV21, CAM_W, CAM_H, yuvI420)
public void yuvScaleI420(byte[] i420Src,int width,int height,byte[] i420Dst,int dstWidth,int dstHeight,int model)
描述:高效的对YUVI420的缩放,速度快,性能高
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| i420Src | byte[] | - | yuvI420的byte数组 |
| width | int | - | 图像的宽度 |
| height | int | - | 图像的高度 |
| i420Dst | byte[] | - | 缩放后的yuvI420数据 |
| dstWidth | int | - | 缩放后图像的宽度 |
| dstHeight | int | - | 缩放后图像的高度 |
| model | int | - | 缩放模式 ,0-3,质量由低到高 |
- 返回 无
示例代码:
aidUtil.yuvScaleI420(yuvI420, CAM_W, CAM_H, yuvI420_640x360, CamW_640, tmpHeight_360, 0)
public void yuvI420ToRGB24(byte[] i420Src,int width,int height,byte[] rgb24Dst)
描述:对yuvI420转RGB24,速度快,性能高
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| i420Src | byte[] | - | i420Src格式的byte数组 |
| width | int | - | 图像的宽度 |
| height | int | - | 图像的高度 |
| rgb24Dst | byte[] | - | 转换后的rgb24Dst数据 |
- 返回 无
示例代码:
aidUtil.yuvI420ToRGB24(yuvI420_640x360, CamW_640, tmpHeight_360, rgb640x360)
public byte[] yuvCropI420(byte[] i420Src,int srcWidth,int srcHeight,int croppedWidth,int croppedHeight,int startX,int startY)
描述:对yuvI420进行裁剪
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| i420Src | byte[] | - | i420Src格式的byte数组 |
| srcWidth | int | - | 图像的宽度 |
| srcHeight | int | - | 图像的高度 |
| croppedWidth | int | - | 被裁剪图像的宽度 |
| croppedHeight | int | - | 被裁剪图像的高度 |
| startX | int | - | 裁剪起点的X |
| startY | int | - | 裁剪起点的Y |
- 返回
| 类型 | 描述 |
|---|---|
| byte[] | 被裁剪后的图像i420的字节数组 |
示例代码:
byte[] croppedI420Data = aidUtil.yuvCropI420(yuvI420,CAM_W,CAM_H,croppedWidth, croppedHeight, startX,startY)
public void imageToNV21(Image image,byte[] nv21)
描述:对mipi使用Camera2 回调的Image对象,提取NV21字节数组。因为安卓使用camera2,获取的数据为image。
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| image | Image | - | camera2 的回调数据 |
| nv21 | byte[] | - | 提取的nv21字节数组,byte数组的大小要对 |
- 返回 无
示例代码:
aidUtil.imageToNV21(image, NV21)
工具类.class Yolov5Util
此类为开发者提供的友好工具类。提供了友好工具函数,针对yolov5的模型提供高性能的预处理函数,后处理函数。开发者直接可以开箱即用,更快的进行推理后的预处理、后处理操作。
Public Member Functions
public ArrayList <Recognition>postprocess(float[] res0,float[] res1,float[] res2,int shape,int classNum,float objectThreshold,float nmsThreshold,ImageDimArrange imageDimArrange)
描述:对yolov5的模型在模型推理成功之后,获取到数据,进行后处理的友好工具函数。
- 参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| res0 | float[] | - | yolov5模型的第一个输出floats数据 |
| res1 | float[] | - | yolov5模型的第二个输出floats数据 |
| res2 | float[] | - | yolov5模型的第三个输出floats数据 |
| shape | int | - | 模型的shape |
| classNum | int | - | 模型的分类个数 |
| objectThreshold | float | - | 目标置信度 |
| nmsThreshold | float | - | 交并比阈值 |
| imageDimArrange | ImageDimArrange | ImageDimArrange.NHWC | 图像的输出通道序列,有可能是NHWC,也有可能是NCHW,默认值是NHWC |
- 返回
| 类型 | 描述 |
|---|---|
| ArrayList | 目标类的集合 |
示例代码:
// --------------------7. Postprocess ------------------ //
List<Recognition> recognitions = yolov5Util.postprocess(outputTensor0.floats, outputTensor1.floats, outputTensor2.floats, inputShape, 40, mObjectThresh,mNmsThresh)
Demo运行
Aidlite SDK for Android提供了一个简单可运行的安卓工程Demo,其中包括了三种量化的模型:
- Unet(缺陷检测)
- ResNet18 (分类)
- YOLOv5s(目标检测)
- CPU绑定例子
Aidlite SDK for Android的可运行安卓工程下载链接 (SNPE对应版本请参考Aidlite SDK版本支持矩阵):